1. Introduction[edit | edit source]
In the STM32MPU Embedded Software distribution, the RPMsg protocol allows communication between the Arm® Cortex®-A and Cortex®-M cores [1] [2].
To implement a feature relying on RPMsg protocol, it is important to understand that this protocol has not been designed to directly transfer high data rate streams. As a result, the implementation needs to be adapted depending on the use case constraints:
- For control and low data rate exchange, RPMsg is enough.
- For high rate transfer and large data buffers, an indirect buffer exchange mode should be preferred.
It is not possible to provide strict rules for choosing one or the other implementation. This depends on the use case but also on:
- the loading of the Cortex CPUs,
- the process priorities,
- the preemptions (such as interrupts and secure services),
- other services implemented on top of the RPMsg instance,
- ....
However, as shown in the How to exchange data buffers between processors article, for a data rate less than or equal to 5MB/s, the direct buffer exchange mode is recommended (as it is easier to implement than the indirect buffer exchange mode).
The aim of this article is to help choosing the best adapted implementation. If this is not sufficient, another approach is to implement first the direct mode and test its performance in your system.
2. RPMsg protocol awareness[edit | edit source]
The RPMsg provides, through the virtio framework, a basic transport layer based on a shared ring buffer:
- The buffers are prenegociated and preallocated during initialization step (size , number of buffers).
- The buffers are allocated in non cacheable memory.
- There is no direct access from RPMsg client to these buffers. They are filled by a copy (no zero copy or DMA transfers).
- No bandwidth is guaranteed. Buffers can be shared between several RPMsg clients.
The size of the buffers is hard-coded (512 bytes). However it is possible to customize the number of buffers used. Modifying this parameter impacts the number of buffers allocated in both direction (refer to resource table for details).
A doorbell signal is associated to each RPMsg transfer. It is sent to the destination processor via the stm32 IPCC mailbox and generates an IRQ for each message transfer.
Notice that the IRQ frequency can be a criteria for the decision. For instance a 1 Mbyte/s transfer from Cortex-M to Cortex-A generates around 2000 IRQ per second on each Cortex, to transfer 512-bytes RPMsg buffers.
3. Direct buffer exchange mode[edit | edit source]
This mode consists in using the RPMsg buffer to transfer data between the processors.
- The RPMsg message contains effective data.
- Memory allocation is limited to the RPMsg buffers allocation.
- RPMsg client implementation is quite straight forward in terms of code implementation.
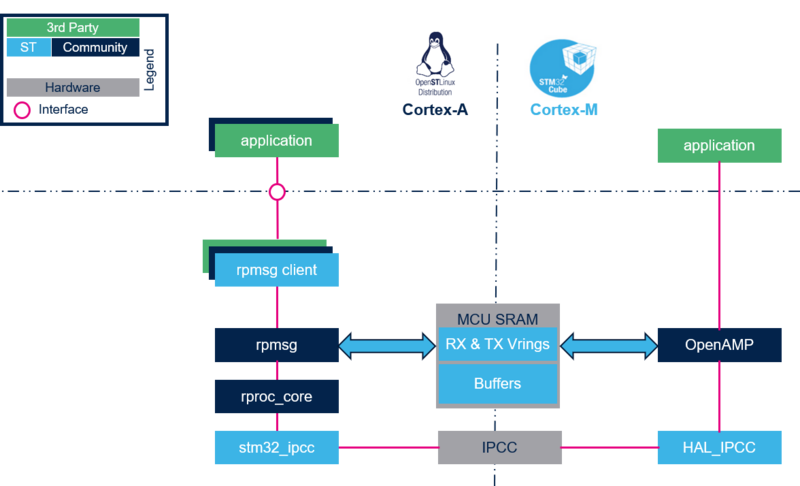
The Direct buffer exchange implementation is recommended:
- for control message, for instance to control a remote processor application,
- to exchange low data rate stream (similar to a slow data rate bus).
For application sample, refer to:
- the "OpenAMP_TTY_echo" application example in the list of STM32CubeMP15 available projects and in the list of STM32CubeMP2 available projects,
- the How to exchange data buffers between processors article that provides source code example for the direct buffer exchange mode.
4. Indirect buffer exchange mode[edit | edit source]
This mode is also called "large data buffers exchange" or "Big Data". It consists in using RPMsg to carry references to some other buffers that contain the effective data. These other buffers can be:
- of any size,
- allocated by multiple means, in cached or non cached memory, DDR or MCU SRAM, ...
- mmapped for direct access by application,
- accessed by DMA or any master peripheral.
This implementation allows limiting data copy between producer and consumer, offering direct data access to buffer clients such as applications.
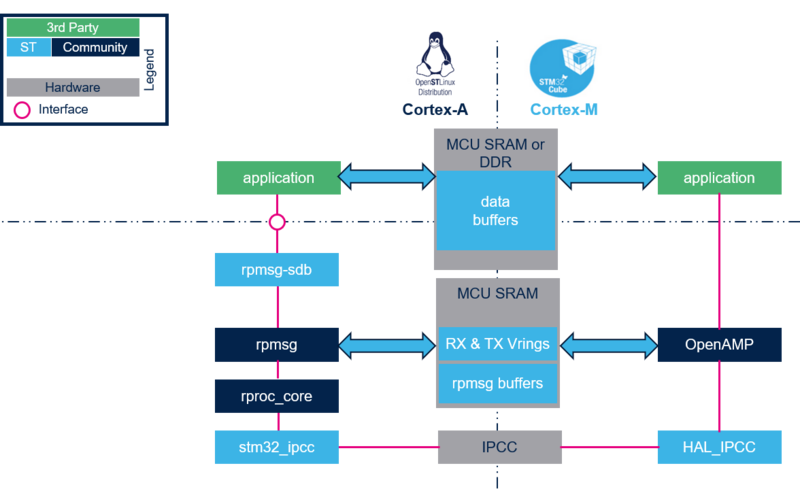
In the above overview, rpmsg_sdb is a driver taken as an example. It offers to the application an interface to allocate and exchange buffers with the remote processor.
This implementation is recommended:
- for high bit rate transfer,
- for real time transfer (e.g. audio buffers),
- to privilege dynamic buffers allocation and/or minimize copies.
- to adapt to existing Linux framework or application
- ...
For application sample (and source code), refer to the How to exchange data buffers between processors article.
5. References[edit | edit source]
Arm® is a registered trademark of Arm Limited (or its subsidiaries) in the US and/or elsewhere. ![]()
Arm® is a registered trademark of Arm Limited (or its subsidiaries) in the US and/or elsewhere. ![]()